Comparing Two Proportions
STAT 218 - Week 5, Lecture 3
Notation
- To be able to differentiate two samples from each other, we will use subscript.
- The two populations that we are interested in can be either
- naturally occurring populations (Figure 1) OR
- conceptual populations defined by certain experimental conditions.
Motivating Example - II
The GSS asks the same question, below are the distributions of responses from the 2010 GSS as well as from a group of introductory statistics students at Duke University:
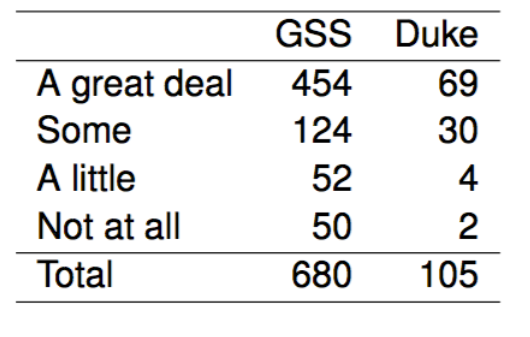
Parameter of interest: Difference between the proportions of all Duke students and all Americans who would be bothered a great deal by the northern ice cap completely melting.
Point estimate: Difference between the proportions of sampled Duke students and sampled Americans who would be bothered a great deal by the northern ice cap completely melting.