# A tibble: 1 × 7
statistic t_df p_value alternative estimate lower_ci upper_ci
<dbl> <dbl> <dbl> <chr> <dbl> <dbl> <dbl>
1 1.99 12.8 0.0679 two.sided 4.90 -0.418 10.2Comparing Two Means
STAT 218 - Week 6, Lecture 3
Let’s Remember

A Quick Snapshot

Independent-Samples t test

Notation
- We employed a parallel notations but to be able to differentiate two samples from each other, we will use subscript.
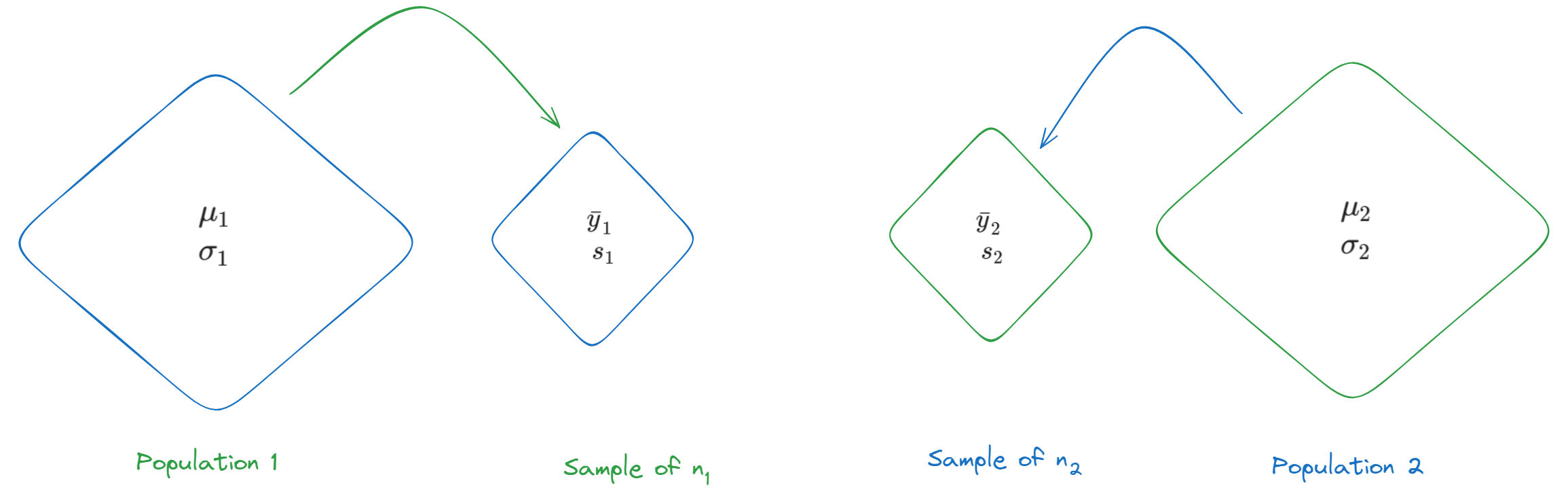
- The two populations that we are interested in can be either
- naturally occurring populations (Figure 1) OR
- conceptual populations defined by certain experimental conditions.
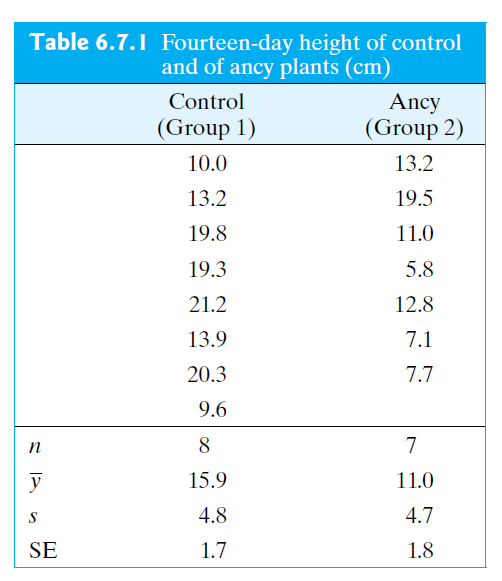
An Example
The Wisconsin Fast Plant, Brassica campestris, has a very rapid growth cycle that makes it particularly well suited for the study of factors that affect plant growth.
In one such study, 7 plants were treated with the substance Ancymidol (ancy) and were compared to 8 control plants that were given ordinary water. Heights of all of the plants were measured, in cm, after 14 days of growth.
(\(df\) for this question is calculated as 12).
Let’s see an example for hypothesis testing.
Interpretation of R Output

Type I Error vs Type II Error
- Table 7.3.2 displays the situations in which Type I and Type II errors can occur.

- For example, if we find significant evidence for \(H_A\), then we eliminate the possibility of a Type II error, but by rejecting \(H_0\) we may have made a Type I error.
Type I Error vs Type II Error

From Essential Guide to Effect Sizes by Paul D. Ellis (2010)